Intro
I've been recently revising my data backup strategy. This is a brief summary of my considerations and the solution finally adopted.
Objective and scope
The objective is to identify a safe backup strategy for some of my personal and work related data. My focus is on two primary aspects of data safety, confidentiality (i.e. protection from unauthorised access) and recoverability (i.e. protection from data corruption and data loss).
Disclaimer: I'm not interested in a universal backup strategy, just something simple that works in my particular case. Your mileage may vary and you might need a more sophisticated approach.
I procedeed along these steps:
- Create a data inventory.
- For each data set in my inventory, consider its confidentiality and recoverability requirements.
- For each level of confidentiality and recoverability, define an appropriate backup mechanism.
- Select the backup software, provision the servers, and write the configuration scripts.
- Set up appropriate monitoring mechanisms.
- Write documentation and create a disaster-recovery plan. The plan should define a schedule of disaster-recovery dry-runs and a mechanism to manage encryption passwords.
Data inventory
I started by reviewing my data inventory, the list of data sets that are produced, collected, processed, or otherwise managed on my system(s). I listed the confidentiality and recoverability requirements of each data set.
For example:
| Data set | Confidentiality | Recoverability |
|---|---|---|
| Password manager database | Critical | Critical |
| Burn-after-reading message | Critical | Ephemeral |
| Bank statements | Medium | Medium |
| Music collection | Low | Low |
| Public software project | Public | High |
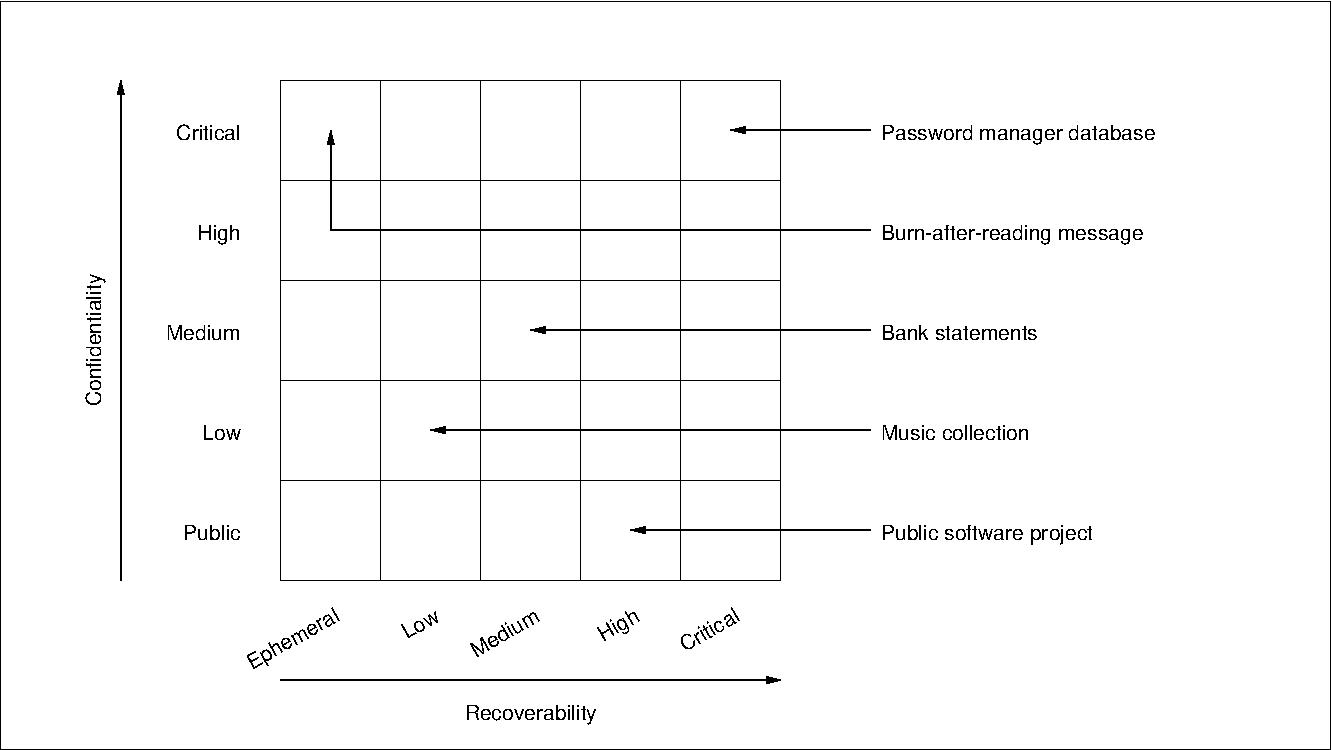
Figure 1: Example data sets corresponding to different confidentiality-vs-recoverability requirements.
How to best backup these data sets on the basis of the respective confidentiality and recoverability requirements?
Backup mechanisms
I selected the following possible backup mechanisms. This should be enough options for my needs:
- No backup: data is not backed up at all.
- Encrypted offline backup: data is encrypted then saved to an offline device, e.g. a USB drive.
- Encrypted on-prem backup: data is encrypted then saved to an on-premises server.
- Encrypted cloud backup: data is encrypted then saved to a third-party cloud server.
- Cleartext cloud backup: data is backed up with no encryption on publicly accessible repositories. You may want to sign the data to guarantee integrity.
In all cases, the following aspects need to be considered to get to a robust solution:
- If it's an encrypted backup, how strong are the encryption algorithm and the password used? How are the encryption passwords managed and backed up? Consider Shamir's secret sharing. Consider durable materials such as these examples.
- What's the number of backup replicas and where are they located?
- What's the granularity of the backup schedule and is it consistent with the Recovery Point Objective (RPO)? What's backup rotation scheme?
- Is the backup software used of good quality and actively maintained? Are the backup servers properly secured?
- When using a third-party cloud server, what are the costs as well as the Service-Level Agreement associated to it.
- Are monitoring mechanisms in place to alert of backup failures?
- Are backups regularly checked via automatic integrity checks and via manual disaster-recovery dry-runs?
Backup strategy diagram
I mapped each confidentiality-recoverability scenario to the backup mechanism that I considered most appropriate. This partly reflects personal priorities and security considerations, your mileage may vary.
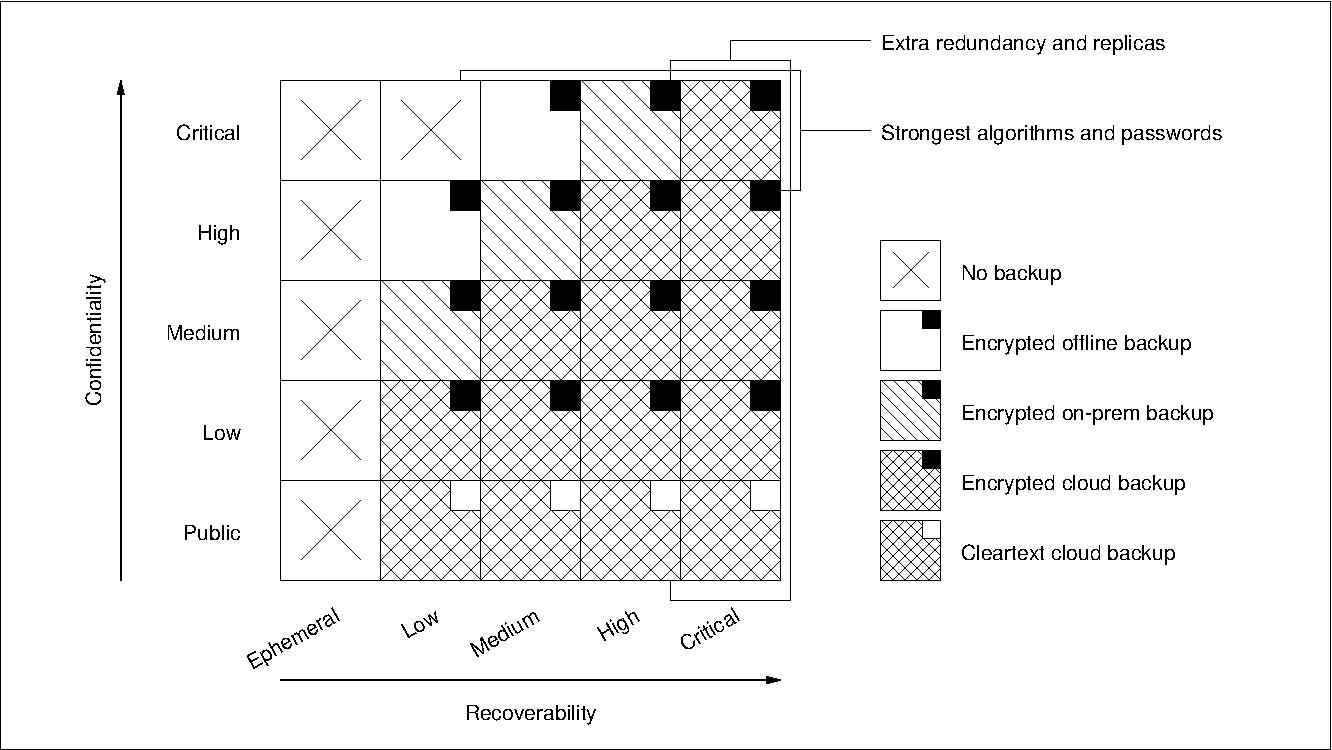
Figure 2: Different backup strategies for different areas of the confidentiality-vs-recoverability diagram.
The diagram should be self-explanatory, but in a nutshell:
- No backup of ephemeral data, i.e. data that with no recoverability requirements.
- Cleartext cloud backup of all public data, i.e. data that with no confidentiality requirements.
- Encrypted offline backup of data with high confidentiality and low recoverability requirements.
- Encrypted on-premises backup of data with high confidentiality and medium recoverability requirements.
- Encrypted cloud backup of data where recoverability is as or more important than confidentiality.
Backup software
I short-listed the following backup applications:
- BorgBackup, backup software that provides data deduplication, compression, and encryption.
- borgmatic, a Python wrapper around BorgBackup that can be configured via a declarative script.
- restic, backup software that provides data deduplication, compression, and encryption; it supports various backends, including S3-compliant storage servers.
BorgBackup
For the time being I'll be using a variation of this Borg-based script for encrypted on-premises backups. This is meant to be run regularly as part of a cron job.
The same script can also be used for encrypted cloud backups where Borg is supported by the server and, with some adjustments, for encrypted offline backups.
#!/bin/bash
# ------------------------------------------------------------------------------
# Bash security options.
set -euo pipefail
# ------------------------------------------------------------------------------
# Environment variables.
BORG_COMMAND=borg
CURL_COMMAND=curl
PASS_COMMAND=pass
# FIXME: These details are just for testing.
export BORG_PASSCOMMAND="pass show <backup_password_entry>"
export BORG_REPO="<backup_host>/backups/laptop"
BACKUP_PATHS="
/home/user/work/
/home/user/personal/
/home/user/.local/share/
"
HEALTH_CHECK_URL=`${PASS_COMMAND} show <backup-healthcheck-url>`
# ------------------------------------------------------------------------------
# Borg actions.
borg_create() {
printf "Create new backup.\n"
"${BORG_COMMAND}" \
create \
--compression lz4 \
--filter AME \
--list \
--stats \
::$(date --iso-8601=seconds)_$(hostname) \
${BACKUP_PATHS}
}
borg_prune() {
printf "Prune the repository.\n"
"${BORG_COMMAND}" \
prune \
--glob-archives '{hostname}-*' \
--keep-hourly 24 \
--keep-daily 7 \
--keep-weekly 52 \
--keep-monthly -1 \
--list
}
borg_compact() {
printf "Compact the repository.\n"
"${BORG_COMMAND}" compact
}
notify() {
printf "Ping the health-check URL.\n"
"${CURL_COMMAND}" \
--max-time 10 \
--retry 5 \
"${HEALTH_CHECK_URL}"
printf "\n"
}
borg_create && borg_prune && borg_compact && notify
Outro
These overengineered ramblings are reported here mostly as a note-to-self but I hope that some elements can be helpful to others. Of course, the most important take-away is: do spend some time to come up with a solid backup strategy, your future self will be thankful.